Sound Reproduction, Semiotics and Computer Music Composition1
Nicola
Bernardini
After
tasting the oranges the peasant had offered to him, the King
expressed his approval with a compliment. Happy and proud of his
produce, the peasant answered, "Your Majesty!
You haven't seen anything yet! With these we feed the
pigs."
2
A recent document
from IRCAM begins with the following statement: "The problems that Musical Research must solve today are
not so much technological as cognitive." (IRCAM - Recherche Musicale, 85/86, p. 1) We
feel that this statement summarizes most incisively a situation that at first glance looks very confused. Despite
the great technological leaps of the recent past and of the
present, computer music -. and, for that matter, music in general - still seems to be, esthetically
speaking, at a very critical point. Indeed, there are many ideas circulating, but few of them seem relevant to
compositional activity.
The aim of this
paper is to penetrate the twists and turns of composition in the Western world
today (including the U.S.S.R.) and to try to point out at least some of its
relevant instruments - both physical and theoretical. Coming from a computer
music composer, this paper might be considered a compositional proposal (though
not in the generative/procedural sense,)
although it must be clear that: 1) it is not intended to be an absolute in any
way; 2) rather, it is a reflection that stems from the compositional activity in the field of computer music; 3) it is not, by
any means, an analysis of the author's own compositions. We would, hope
that what a composer thinks is
quite different from the compositions themselves.
Since the paper will delve into many different fields,
prior works will be mentioned only as they help to clarify specific elements
in the discourse. Moreover, we will try to
convey their meaning and purpose through necessarily short quotations. Of
course, the responsibility for any inaccuracy rests entirely with the
author, who wishes to encourage all remarks, observations and criticisms that
may arise.
Some
Reflections on the Composer's Environment
To understand how a compositional model works in its
related enviornment, it is first necessary to analyze the
reality in which this model exists: that is, post-modern society, in our case.
Cultural activity in post-modern society has been abundantly studied: (cf. for
example, Hassan 1971, Lyotard
1979, Lyotard 1984, Vattimo
1985) we are therefore relieved of the
responsibility of doing it ourselves. So, let us underline what we consider
to be its most important characteristics. In post-modern societies "[narrative
function] shatters into clusters of
narrative, but also denotative, prescriptive, descriptive, etc.
linguistic elements, each carrying within itself some sui
generis pragmatic valency
... Thus, the derivating
society is less dependent on a Newtonian anthropology ... than on the pragmatics
of linguistic particles." (Lyotard 1979, p. 8) Lyotard's thesis is that, in this way, this society
produces a "crise du recit," a crisis of the narrative device that, up to
now, has allowed the legitimization of knowledge (cf. Lyotard
1979). All that remains of language as it disappears is an infinite chain of
separate phrases. The uniformity and homogeneity of this condition can be
broken up only into that "instant of language in which something that must
be expressed in phrases cannot be expressed yet." (Lyotard
1984) This "lag" is the "difrerend"
which indicates a verbal surplus in respect to human will and which casts doubts on the concept of "a language
naturally at peace with itself, 'communicational' and agitated solely by
human will, passion and intention" (Lyotard 1984). Of course, this involves many ideological
and political implications which, although important, are beyond the
scope of this paper.
Paradoxically,
this new nihilism, this "pensiero debole" (cf. Vattimo et al.,
1983) produces "a subjectivity without
a subject" (cf. Blanchot 1983) which
incorporates in itself its own contradiction: a "strong"
element of hope and survival. In fact, it is not surprising that hermeneutic
philosophies are now claiming a "return to the subject" (cf. the 77th
issue of Langages, Paris, March, 1985),
by re-evaluating thinkers like Beneviste and Ricoeur and their
fight against "the outline of a transcendentalism without a subject" (cf.
Ricoeur 1963) operated by structuralism.
The
Status of Sounds
In
the society described above, sound is trying to establish a new identity after
the irreversible transformation undergone via the development of sound
reproduction techniques. This transformation
has been thoroughly analyzed from the sociological point of view (cf.
for example Adorno 1963; Benjamin 1974; Adorno and Eisler 1977; Mayer 1985). The outcome of these studies has produced
many considerations which are indeed valuable
for the electronic and tape music composer (cf. Stoianova
1983). The loss of the traditional "hic et nunc,"
the "aura" (cf. Benjamin 1974) of the reproduced work of art, which
becomes "more and more the reproduction of a work of art designed to be reproduced"
(cf. Benjamin 1974) is something with which most of us deal closely on a day to
day basis. On another level, "the
influence of the various ramifications of media industries (...) has induced
... a deep change in the 'music' institution as it has been handed down to us through history and of the functions and
structures of both old and new music" (Mayer 1985, p. 119).
Willingly or not, as musicians we are part of this change and it would be
foolish to ignore it.
Still, we find that something in these sociological
studies has been neglected, that is,
sound itself, along with today's human perception of musical structure in the
era of their reproducibility. However, other authors, from not specifically
musical fields, have provided appropriate insight into these matters. McLuhan, for one, by analyzing the transformations introduced by typographic technologies (cf. McLuhan 1962) has given us good clues as to what
happens during and after media revolutions.
Music Notation and Music
Reproduction
Referring to the transformations introduced by the
phonetic alphabet, McLuhan wrote that "a new kind of
processing of problems, one thing at a time, simultaneous mosaic, a dealing
with many aspects and levels of meaning in crisp simultaneity. This method will no longer serve in the new (alphabetical and
typographical) lineal era" (McLuhan 1962, p. 129). This "linearity" of processing, transposed to the
introduction of music printing
shortly after typography, has contributed to the sequential development of tonality
(a phenomenon that McLuhan himself noticed - cf. McLuhan 1962, p. 61). Here too, some self-evident facts
hide a deeper transformation, the influence of which is still being felt (cf.
below). The proliferation of the madrigal, of the French polyphonic "chan-«son and of
lute tablatures are strictly connected to the expanding market directed towards
the new bourgeois classes and the urban aristocracy, a market enhanced beyond imagination
by the new-born music publishing business. But we are allowed to think that, if music printing changed the
target of compositional activity from a religious to a more lay (though not yet entirely bourgeois), it then
set the basis for a music in perpetual lineal development.
That is, a development based on sequential transgression of the rules set forth
in precedence. The tempered tonal system served as an excellent starting point because of its strong grammar, and has lasted for
300 years (a long time considering how weakening
each transgression has been). This is the model of music composition evolution we
have inherited, and which, as we shall see, is still very much alive.
It is reasonable to consider that the simultaneity between the shattering of the
tonal system (and subsequently, of its development model) and the birth of sound
reproduction was a mere coincidence.
Nevertheless, this simultaneity rendered the crisis which music had been
suffering in this century exceedingly profound. Considering
digital developments, we may not agree with McLuhan's
prediction that "our" world shifts from a visual to an auditory orientation in its electric technology" (McLuhan 1962, p. 26). "On one hand, the
oscillation... from visual to auditory space took human consciousness back to
a sensorial oneness...: on the other hand, this return was not structured as a
simple return to a pre-alphabet past"
(McCaffery, 1983, p. 73). This means that the mind is
now able to maintain its linear epistemologic habits
in a multi-dimensional perceptual world, which brings us back to the post-modern situation we envisioned at the
beginning of this paper. And as we suspect that sound reproduction
involves far deeper transformations than
music printing did, we are bound to think that, instead of synthesizers, digital
technology, etc., sound
reproduction, as a modifier of our oral, perceptual structures, is really the
instrument of a new kind of compositional evolution, which must not be confused
with a new kind of composition.
The Musical Sign's Status Today
Goodman
(cf. Goodman 1968, p. 99 and also cit. in Eco 1975, p. 241) makes an important distinction between
"autographic" and "allographic arts:
"the former cannot be notated
and does not contemplate performance, while the latter can be translated into
conventional notation, and the resulting 'score' can be performed, with
a certain freedom of variation (i.e. music)" (in Eco 1975, footnote in p.
241). Eco then specifies that this distinction is derived from the opposition
between "dense vs. discrete" signals. A "dense" or
continuous" signal is one for which it is difficult to determine
generating rules making any kind of replica impossible (i.e. paintings, cf.
Goodman 1968, Eco 1975). This is not without
consequences, because, in language theories, dense signals have often been considered
to constitute symbolic monoplaner systems. That is,
they are not interpreted, rather, they tend to be interpretable (cf. Hjelmslev
1943). And even when someone like Eco tries to establish a system for
these signals, he is obliged to limit himself to very vague terms like "textual
galaxies," "open signals," "propositional structures"
and so on (cf. Eco 1975, par. 3.6.6). This is because of the non-segmented
nature of these signs which will not allow precise and definite articulation.
Since music has always been "reproduced" by
means of conventional notation it is usually considered to be constituted by
"discrete" signals. We want to point out that this conception of the musical sign
is only partially correct, since it works only because of notation. It would
seem, then, that musical signs behave like verbal ones, constituting some sort of dichotomy like that proposed by Saussure (the dichotomy langue-parole; cf. Saussure 1922, chap. III) or that suggested by Pike (the
subdivision of emic-etic; cf. Pike 1947, chap. II). Many musicologists and linguists
have adopted these schemes to represent music in terms of language (cf. Springer 1956, Buyssens
1967; Bright 1963; Nettl 1971; Chenoweth 1972;
Nattiez 1975). Nattiez (Nattiez 1975, pp. 76 and ff.) has foreseen in the adaptation of music to the langue-parole dichotomy
some of its limitations, and has tried to demonstrate that this dichotomy
automatically generates a trychotomy as in Figure 1 (Nattiez, op. cit. p. 82):
LANGUE PAROLE
Reference
system Composition
Notated
Composition Particular Interpretation
LANGUE PAROLE
Figure 1
However, since "the tonal system [among other
reference systems] exists only for harmony treatises and manufacturers,
for whom 'grammatical' rules are in fact stylistic rules' (Nattiez op. cit. p.
84), our author discovers, "between the single composition and the tonal
system, ... an infinity of stylistic levels" (p. 82). But this does not
eliminate the affinity between verbal
language and musical language since Nattiez himself
writes a little later that "it is extremely interesting to establish that
it is impossible, in the musical field, to depend on one single
pertinence level much in the same way as linguistics have been forced to refine the Sausurrian
dichotomy langue-parole" (p.
86, italics ours). Evidently the problem is elsewhere.
The fact is that, from the
"notation-as-means-of-reproduction" point of view, rather
than a discrete signal, sound behaves like a so-called "dense"
signal. Following the definition given by Eco of such signals, "given a
perceptual model as a 'dense' representation of a
certain experience, assigning to the perceived object x the properties
xl, x2, x3, .... , xn,
as soon as the cultural experience is carried out the perceptual model
originates a semantic model that keeps only a
few properties of the 'dense' representation" (Eco 1975, p.
312, italics ours). Which is exactly what happens with music
notation.
We believe that the mistake of considering sound a
'discrete' more than a 'dense'
signal is due to the fact that we think of music in an old fashioned way, while
experiencing it through the contemporary
world of reproduction and media. This mistake has given rise to many
inconsistencies in the study of musical signs. To begin with, we think that the
difficulties encountered in establishing pertininence
levels by means of the classical operation
of commutation (cf. Hjelmslev 1961), among others,
has led many musicologists to think
of music as a monoplanar language (cf. for example, Imberty 1975, p. 70; Jakob-son
1983, p. 14; Delalande 1953, p. 53) as do the exponents
of the traditional formalist theory (cf. Hanslick
1893; Stravinsky 1942; Langer 1951, etc.). This, in turn, has led the theorists
who believed in a musical language not purely syntactical but provided with a semantic depth, to think of the semantic
connotations of music in terms of referential connotation exclusively
(cf. the extreme example of Cook 1962; but also Meyer 1956; Osmond-Smith
1972; Imberty 1976; and to a certain extent Lissa 1976; Stefani 1976). It is
worth noting, however, that the problem of a semantic level of music has been
debated for
more than a century now, and it is still very confused.
Once again, sound reproduction comes in very handy, because of its ability to
subdivide
the sound continuum into segments as small as desired. It is clear that sound reproduction is an innovation
comparable to that of the phonetic alphabet and of movable type, while
the representation of sound and music given by music notation is, at best, comparable to the representation a good photograph
can give of a work of art. The lack of a
means of segmentation in music has oriented its perception in the past towards
a purely denotative system of signs (except in the case of program music
in which, although the referents were coded
quite artificially, some semantic capability of music was thus demonstrated).
Sound reproduction (and its corollaries, such as music diffusion etc.) has
allowed our perception to grasp new connotational levels that were simply inconceivable before.
Of course, it is the appearance of
digital technology that clarifies beyond doubt the potential of segmentation, falsification, and of
connotation production inherent to sound reproduction. Other problems
raised by musicologists during the time of analog sound reproduction, such as
the problem of a scientific analysis of musical interpretation (cf. Ruwet 1975, p. 34, just to make an example of a problem
clearly dictated by the new status of musical sign), can now be solved with
digital means (cf. Clynes 1984). In this frame of
ideas, it is not surprising that the computer music community has spent a lot
of is time trying to establish if a certain
technique or a certain machine is able to reproduce natural sounds,
insisting on the fact that this is not done for a musical reason but for an
experimental one. There are very
good musical reasons to do it, and computer music
composers are starting to become aware of them
(cf. Barriere 1984, p. 182).
Possible Models of Compositional Development
It
is evident now that our traditional lineal compositional models need to be revised under this new light. The ambiguity and depth of
the new poetic message in music will not be
described by lineal development of, for example, a new musical variable to be
serialized or some new more or less designed stochastic process (cf. Thomson
1983). It should be clear that, after
4'33" by John Cage, there can no longer be any lineal "transgression of rules" in music
(significantly enough, Cage begins his book Silence with the following
sentences (cf. Cage, 1973, p. xii):
nothing is accomplished by writing a
piece of music our ears are now
nothing is accomplished by hearing a piece of music now in
excellent condition
nothing is accomplished by
playing a piece of music
Rather, the poetic spark of music might be created,
today, by the connotational ambiguity of the present time
multi-dimensional musical language. That is, music is getting closer and closer
to the mechanisms of poetry. Which means, in short, that
music has finally acquired the possibility of becoming its own meta-language.
This possibility was forseen by a few perspicacious
investigators (cf. Levi-Strauss 1964; Court 1971; Eco 1975) and composers
(among others Mahler, Berg, Ives, Nancarrow, Berio, Schnitke).
But, due to technological and theoretical limitations, the full potential of
this model is far from being realized. The
authors we have just mentioned do not push themselves much further than sophisticated
quodlibet and quotation techniques.
A general model for
semantic representation which works quite well in music is the MSR model
elaborated by Eco (cf. Eco 1975, par. 2.11 - MSR
stands for Semantically Reformulated
Model) and adapted to
specific musical examples by Stefani (cf. Stefani 1976, pp. 220 and
ff.). Up to now, however, it has served to
demonstrate specific referential connotation
capabilities of functional music. It is particularly meaningful that in Stefani's study,
the examples used are jingles for advertisement, a genre closely dependent on
sound reproduction. The model is
represented in Figure 2. MS (marche sintattiche) represent the syntactical marks
that allow the signifier to be combined "with other signifiers so as to produce well formed and grammatically acceptable
phrases even though they are anomalous ... and therefore to define as
unacceptable other phrases that would instead make
sense from a semantical point of view" (Eco op.
cit p. 133; " the d's and the c's are denotations
and connotations ... (" denotative ... marks ...constitute ... the
cultural unit to which the signifier
is primarily related and on which successive connotations are based. ... connotative
... marks ... contribute to one or more cultural units expressed by the sign
function previously constituted" Eco op. cit p. 123); "(cont)'s are
contextual selections, which give instructions of the type 'finding (conta) use the following d's
and c's when the sememe
is contextually associated with an <<a >> sememe'
(circ)'s are circumstantial selections,
which give instructions of the type 'finding (circ);s use
the following d's and c's when the signifier that
corresponds to the sememe is accompanied situationally by the event
or object 11=11 which must be intended as a signifier pertaining to another
semiotic system*" (Eco 1975, p.
153). "The contextual selections file other sememes
selections file other signifiers ... which belong to different semiotic systems,
or objects and events gathered
as ostensive signs, usually occurring with the corresponding signifier
of the represented sememe" (Eco 1975, ibid.).
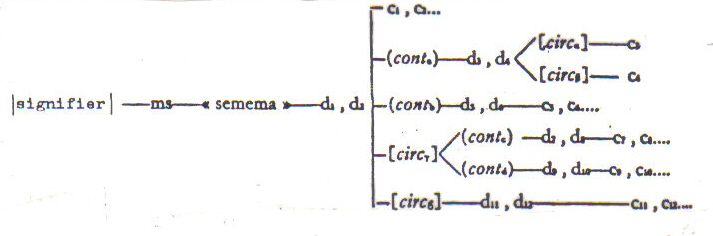
Figure 2: after
Eco, U. 1975, Tratto de Semiotica
Generale, Bompiani,Milano. (Reproduced
with the permission of the author and the publisher.)
This model is a
good starting point of understanding music as it is perceived in our era. Even
by using an approach limited to strongly programmatic music (jingles), Stefani can demonstrate that "the MSR allows the
integration in a homogeneous manner on one
single level, of sign occurrences that are usually considered 'special', if not
anomalous, by musicologists, as in
the case of quotation ... As a matter of fact, quotation is reduced in the MSR to a mark like any other, simply decoded
on the basis of a given selection" (Stefani
1976, p. 210). We add to this that the MSR can also describe connotations that do not have external referrents.
Rough examples of verbally expressed connotations could be: "pointillistic" or "sounds like Debussy" or " pianistic articulation,"
etc. - expressions which serve to show how
much rougher verbal language is when speaking of music than are the
connotations themselves.
Another
important feature of the MSR is that it can explain why the same composition can be "heard" in many different, even opposite
ways, by different people. Itdepends on the different amount of selections that each
listener can perform (for a similar approach,
cf. Nattiez 1975, p. 74). This means that the MSR
model is able to explain different cultural
approaches (cf. Stefani 1976, ibid). However, the MSR
model is not perfect. Eco himself
underlines its deficiencies, noting that "every
mark constitutes ..., inside a
sememe, some sort of embedded sememe that
generates its own branching and so on ad infinitum. ...How is it possible to represent such a semantic universe,
especially when it is exactly the
semantic universe in which human beings live?" (Eco ibid,
p. 174). This problem is particularly felt in music, where syntactic
marks and semantic marks of signifiers of different nature (i.e. pitch,
rhythm, synchronic and diachronic form, timbre, instrument, techniques, spatial relationships, etc.) are often tightly
intermingled together to give very specific and meaningful results (this
has also been noticed by Stefani; cf. Stefani 1976, p. 209).
For example, it is as if, on top of enumerating strict denotations and connotations,
we tried to specify all the paralinguistic activity (i.e. facial expressions,
intonation. gestures, etc.) that occurs when
someone speaks (a manipulation of these parameters, as a matter of fact, has
already taken place in some musical pieces, such as Amirkhanian's
The Real Perpetuum Mobile or
some of Charles Dodge's compositions).
As a possible solution to this problem, Eco mentions the
Q model, named after its creator M. Ross Quillian (cf. Quillian 1968). The Q model is a model of semantic memory that
allows a certain degree of analysis of semantic processes of understanding.
Unlike the MSR model, in which the structure is based upon a number
of different elements and all elements are in the same dimension, the principal
characteristic of the Q model resides in its two basic elements and seven
linking categories in which elements are in n dimensions (or planes) n being the
number of elements that the model includes. It is a model essentially based on
defining "linking types" as opposed to the earlier one based on
defining
element types" (however, some rough similarities between the two models
can be found -as we will see further on). "The
memory model consists basically of a mass of nodes interconnected by
different kinds of associative links. Each node may be thought of as
named by an English word, but by far the most important feature of the model is
that a node may be related to the meaning (concept) of its name word in one of
two ways. The first relates directly: i.e., its associative links may lead
directly into a configuration of other
nodes that represent the meaning of its name word. A node that does this is
called a type node. In contrast, the second kind of node in the
memory refers indirectly to a word concept by having one special
kind of associative link that points to that concept's
type node. Such a node is referred to as a token node,
or simply a token" (Quillian op. cit, p. 234). The similarity between type node and
denotation and token node and connotation is noticeable. "In the memory model, ingredients
used to build up a concept are represented by the token nodes naming other concepts, while the configurational
meaning of the concept is represented by the particular structure of interlinkages connecting those token nodes to each other.
It will be useful to think of the configuration of interlinked token nodes that represents a single concept as
comprising one plane in the memory. Each and every token node in
the entire memory lies in some such plane and has both its special associative links pointing within the plane
to other token nodes comprising the configuration.
In short, token nodes make it possible for a word's meaning to be built up from
other word's meaning as ingredients and at the same time to modify and
recombine these ingredients into a new configuration (ibid.). Figure 3
is an example concerning the representation
of the three meanings of "plant" as they are described in a
dictionary. "The three circled
words, of the three planes, represent type nodes; every other work shown in Figure
3 represents a token node.
The non-terminated arrows from tokens indicate that each
has its special pointer leading out of its plane to its type definition, i.e.,
to a type node standing at the head of its own plane
somewhere else in the memory. Each of these planes, in turn, is itself entirely
made up of
tokens, except for the type word that heads it (...) Therefore,
the over-all structure of the complete
memory forms an enormous aggregation of planes each consisting entirely of token nodes except for its 'head' node, which is always a type
node" (Quillian, op. cit, p. 242 and ff.). "As to the nature of the
nodes themselves, it will be assumed that these correspond not in fact to words, to sentences, or
to visual pictures, but instead to what we ordinarily call 'properties' ... Representing a property requires
the name of something
that is a variable, an attribute, plus some values or range of values of that
attribute. This feature is achieved in the memory model by the fact that every
token is considered to have
appended to it a specification of the appropriate amount or intensity in the
particular concept being defined .... These values
allow encoding restrictions to a fineness of nine gradations, i.e., permit nine degrees of 'absolute
discrimination' to be represented" (Quillian, op.
cit. p. 242). This means that "the model's range readings on tags
[appended to each node], together with its ability to form disjunctive sets of
attributes, provide it with a ready
facility for representing information having a great deal of vagueness. This is essential. It is the very vagueness of the meaning of most
language terms that makes them useful" (Quillian, op. cit., p. 245, italics ours).
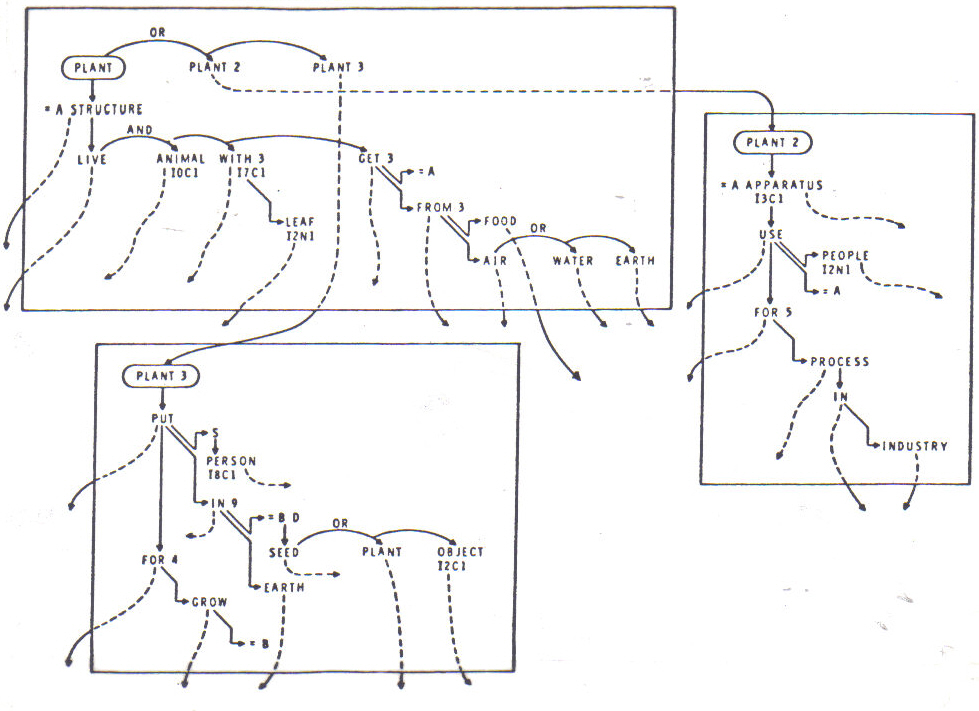
PLANT.
1.
Living structure
which is not an animal, frequently with leaves getting
its food from air, water
earth.
2.
Apparatus used for any process in industry.
3.
Put (seed, plant, etc.) in earth for growth.
Figure 3: after Quillian,
M.R. 1968 "Semantic Memory", in
Semantic
Information Processing,
(Minsky,
M.,
ed., MIT Press, p. 236).Reproduced with the permission of the author
and the publisher.
This
fairly detailed description of the Q model is necessary in order to clarify
potentialities and problems concerning the use of this model in music. The Q
model proves to be a good analysis method
because, not being a generative but a semantic model, it provides the following features: 1) it
embodies, as we have seen, meaning ambiguity and vagueness;
2) it is possible for the system to make inferences (described as
'plane-hopping': cf. Quillian, op. cit. p. 251); 3)
the system can operate structure modifications by itself; 4) finally, it is
n-dimensional, allowing the different semiotic planes of music (or of any other
language) to be linked together. Actually, the possibility of adaptation of
this model to
music seems to be dependent mainly on
the possibility of expressing links in terms of musical objects, an operation
that, at first, sounds quite remote. However, speaking of visual memory, Quillian
states that " it seems at least as reasonable to suppose that a single store
of information underlies both 'semantic' memory and 'spatio-visual'
memory; their difference being not in the
structure of the information sorter, but rather in the way that the static information of that store is used' (Quillian, op. cit. p. 239). Once again, segmentation of a continuum (in this
case, the visual one) is the conclusive condition for semantic proliferation; this condition
is now possible in music by means of sound reproduction.
There
were a few problems in the 1968 version of the Q model, some of which were more of a technical nature and may well have
been solved by now (Quillian, op. cit. par.
4.5). But one of a more structural nature undermined many of its possibilities:
it was, basically a deterministic model. The idea of memory as a huge
dictionary, derived from the Katz-Postal model (cf. Katz and Postal 1964, a
model that Quillian himself criticized: cf. Quillian, op.
cit p. 265), inflates the Q model into " an enormous aggregation of plans"
(Quillian, op. cit p. 237) which seems to have little
relation to a normal human memory (as Minsky wrote in
the introduction of the same book, "I have never heard of any instance that seriously suggests that a
person can hold many millions of independent facts" (cf. Minsky 1968, p. 25). In his
book, Eco asserts that the competence of a subject is more similar to an encyclopedia than to a
dictionary (sf. Eco 1975, par. 2.10.2) and that "the
fact that, ..., the encyclopedia looks more like a Speculum Mundi than an Encyclopaedia Britannica, suggests the idea that the natural language universe is very far from
the universe of formal languages and
has instead a lot in common with a 'primitive' universe" (Eco, p. 162). A model that we believe comes even
closer to the target is the memory model of ancient rhetoric: a
non-infinite "container" (a "building" )
in which every "content"
("memory images" and "symbols" ) occupies discrete definite
spaces. The container is "filled-up" with contents whenever a
memory search is needed and the mind " takes a walk" into the "edifices" to find
what it was looking for (cf. on this subject see Yates 1966).
At any rate, a possible way to solve this
problem of the Q model could well be inside the model itself. It resides
in the range tags that are appended to each token node these tags determine
the preferential and secondary meaning paths that might explain both the functioning of human memory
and that of ambiguity in signification.
The
token nodes and their tags constitute what is known as a fuzzy set, that
a "class of objects with a continuum
of grades of membership" (Zadeh 1965, p. 338,
cf. also Zadeh 1971a, 1971b, 1968; Zadeh, Sun Fu, Tanaka and Shimura 1975; Mamdani
and Gaines 1981; Gupta and Sanchez 1982; Schmucker 1983; Wange 1983; Pal
1985; Skala, Termini and Trillas
1984; Kaufmann 1973). The formal definition of it is "a fuzzy set (class) A in X is characterized by a membership
(characteristic) function f suba (x )
which associates with each point in X
a real number in the interval [0,1], with the value of f suba (x ) with x representing the 'grade of membership' of
x to A. Thus, the closer the value of I suba (x ) to unity, the higher the
(Zadeh 1965, p. 339). "Intuitively, a fuzzy set
is a class with unsharp 'boundaries,' that is, a
class in which the transition form membership to non-membership may be gradual
rather than abrupt" (Zadeh 1968, footnote p.
161). " f suba can be defined in a
variety of ways; in particular, (a) by a formula, (b) by a table, (c) by an
algorithm (recursively), and (d) in terms of other membership functions (as in
a dictionary)" (Zadeh 1968, p. 161). Due to the lack of space, it
will suffice here to indicate that fuzzy sets can, as other kinds of sets,
undergo a number of operations such as
identity, complementation, containment, union, intersection, algebraic product and sum, absolute
difference, (fuzzy) relation, and can be convex, nonconvex,
bounded or unbounded (cf. Zadeh 1965). The union,
intersection and complementation operations
follow De Morgan's laws as well as distributional laws; union and intersection operations can be represented by networks of
sieves (analogous to the switch networks of ordinary sets: cf. Zadeh 1965, pp. 342 and ff). It is evident that the wealth
of operations on these sets allow for
quantitative formalization of such things as meaning (" a fuzzy subset of [a universe of discourse] U" cf. Zadeh 1968, pp. 164 and ff) and language
(" a fuzzy binary relation from a set of terms T, to a
universe of discourse U: cf. Zadeh 1968, pp. 168 and ff). Though "completely
nonstatistical in nature" (Zadeh
1965, p. 340) fuzzy sets provide the
necessary tools for extremely "complex or ... ill-defined problems" (Zadeh 1969, p. 469). The implementation of a time-dependent
fuzzy set theory (cf. Lientz 1972, p. 367) could suit some syntagmatic aspect of music particularly well. In general,
fuzzy set theory can complement the Q model to
provide planing schemes often needed in music composition.
Music
Theory References of These Models
Semiology of music would seem the
appropriate field in which to develop these conceptions.
A semiotic musicological discipline began developing in the sixties and became quite
popular in the seventies together with all other semiotic studies. Given the
wide disintegration into small groups which
followed, we will avoid a detailed description, since several fairly
accurate ones are already in existence (Nattiez 1971;
Nattiez 1973:
Nattiez 1975). Many musicological tools have
been elaborated, following different linguistic approaches: we have already
mentioned above the ones that seem relevant to us as compositional models. However, towards the middle of
the seventies musical semiotics seemed to lose momentum. The movement was
undermined by contrasts among different currents (cf., for example Nattiez 1975; Ruwet 1975; Avron 1975, etc.) and changing times in general (cf., for
examples the desemiotization and deconstruction
theories of Lotman 1971; Restivo
1985; Vattimo et al., 1983, etc.).
What is worth considering, though, is that most of these
approaches were designed by musicologists and, of course, work in a musicological
context: they are only marginally useful to composers (except during their
apprenticeship). This does not mean that musicological semiotics or musicology
per se is useless: on the contrary, the role of musicologists is to develop the discourse
about music, a thing that could never be accomplished by composers (with a few notable exceptions). Nevertheless, when we
attempt to use the type of
knowledge found in semiotic musicology in the context of our compositional model,
we run into problems. Let us rapidly analyze a few of them.
The first one is that some musicologists and linguists
believe that music cannot be its
own meta-language, and tend to designate verbal language as the appropriate metalanguage for music (cf. for example Nattiez
1975, p. 45; Stefani 1976, p. 33; Nattiez
1976, p. 3; Jakobson 1983, p. 14). Others, it is
true, do not trust the verbal language as musical meta-language, but nonetheless use it - not
finding anything better suited to the purpose (cf., for example, Baroni 1980, p. 35; Imberty 1975,
p. 90; Osmond-Smith 1972, p. 32). A third group asserts that the verbal
language is absolutely incapable of conveying musical meanings, thus
denying the possibility of existence of musicology itself (cf. for example, Harweg 1972: Barthes 1972; Rosset 1979; Levi-Strauss 1971). But nobody thinks that
music will ever become a meta-language (an exception is constituted by Barthes, who believes that the speaking and singing voice
can be used in the meta-musical sense; cf. Barthes
1972).
The
second problem is the absolute faith these scholars have towards musical graphic lineal notation, conventional and
non-conventional (cf. for example Nattiez 1975; Molino 1975) when we know too well how problematic
such an aspect is today (cf. Manoury 1984). By
relying on notation, it is clear that analyses, even the most precise and
detailed ones (cf. for example, the distributional analyses proposed by Ruwet 1972; Nattiez 1975, etc.) are
bound to be limited to some particular aspects (i.e. formal aspects, melodic
contours and redundancy, subdivided rhythm and meter, etc.) while ignoring others (i.e., the connotational
aspects and, in general all metamusical aspects)
which are often noticed instead by
much criticized and "non-scientific" music critics (cf., for example,
Ivaskin
1985). A different approach to the subject has been given by Cogan who has made
spectrograms of entire compositions and of specific passages (cf. Cogan 1984).
This approach works in the opposite way: it
does not reduce information in the notational process, so that the
reader can freely select which aspect to look for at any given time. The reduction of parameters, necessary for
controlling the process, is subjective, much as
it is when
listening to a piece of music.
The third problem is "scientific legitimacy" . True, in the past it often seemed as if anything
goes" had become the motto of musical analysis and criticism. As a
reaction to this,
an all too understandable tendency to stricter formalization occurred (cf. Stefani 1976; Nattiez 1973; Nattiez 1975). But,
with all the problems we have listed, it should be clear that a "scientific" approach in
musical analysis can be claimed only by people who do not have a very
precise idea of what "science" is, laying themselves open to strong criticism from authoritative figures in the
field (cf. for example, Ruwet 1975; Groddeck 1972). Therefore, it is questionable
whether " scientific legitimacy" is useful
at all.
Actually, these problems do not exist in musical
composition. As in composition, music is its own meta-language. Using semiotic principles
and methods can only enhance the insight and control of musical processes by
the composer. Just to make an example of how different this approach is,
it is possible to show that something like the "double articulation"
of language as expressed by Martinet (that is the subdivision of language in a first level of natural segmentation and a second
level of cultural segmentation - the 'semantic
units': cf. Martinet 1960), a theory very much criticized by musicologists,
could be very useful in establishing the actual meta-linguistic
capabilities of music precisely.
Early Uses of the Computer as a Musical Instrument
It is evident from what we have said
so far that the typical instrument to allow the
development of music in the era of its reproduction is the computer. The
ultimate segmentation abilities a digital system can
operate on the sound continuum need no further
demonstration. Furthermore these abilities can provide such a control on
musical connotative selections that it
is possible to anticipate the definite stabilization of a perceptual articulation system (cf. above and Martinet
1960), the multiplicity of musical
language particles constituting the first level while the second level is built
upon the articulation of the connotations established by the particles. This
preference towards the computer does not
mean that other, traditional instruments cannot be used as well, but
simply that some of them will adapt to this model better than others (i.e.,
voice, percussion, string orchestra vs. piano,
organ, saxophone, etc.). As we mentioned in the beginning, digital signal processing technologies and all
computer related issues are fairly advanced as far as music is concerned. Still, a lot of progress can be made, but the
basics (i.e. synthesis techniques, hardware, etc.) are quite well under
way. The main problem in the use of computers
in music resides with the conceptions most composers have of what to do with them.
In
general, our tendency is to take the model of analog electronic music, and expand it to digital technology; in other words, a
certain unlimited "faith-in-the-machine" tempered only by the
difficulty, for a musician, to enter the digital world. A description referring
to digital techniques such as: " the electronic material, the synthesized
sound gives - in theory - the possibility of creating a decisively new universe,
liberated from the limits imposed
before" (Boulez 1975, p. 28) sounds awfully similar to another one which twenty
years earlier was related to analog technology (" we are on the lookout
for an unheard world of sounds, rich of
possibilities and practically unexplored" -. Boulez 1954, p. 34).
While enthusiastic comments about the possibilities of the computer are not uncommon,
it is interesting to notice that meager results in computer music are often
explained in terms once clearly stated by Xenakis (Xenakis 1981, p. 17):
a) Musicians that use the computer ignore general
theories, especially mathematical,
physical and acoustical theories [why not language theories?]. Their talent,
when they have it, is not capable of penetrating the virgin spaces where only
abstraction can guide their experience...
b)
scientists who have access to computer technology feel a sort of inferiority complex in the face of musical aesthetics ...
They lack experience in an aesthetic field and do not know which
direction to take at all.
Xenakis then proceeds to outline various directions stating that
a fusion between macro-composition
and micro-composition are based on particular geometrical and mathematical properties (cf. Xenakis
1981, p. 18 and fr.) These have strictly nothing to
do with musical semantics, which
indicates a certain contempt of the composer for the empirical data of " how
is his composition going to-sound." It must be clear the we are not criticizing Xenakis' music,
which can be intriguing and beautiful, nor the use of mathematics in music
(of which we just gave an example cf. above in discussing "fuzzy sets" ). All we are trying to say is that the semantical aspects of that music are either based on the
very empirical "taste of the composer" (referred to as
"talent" by Xenakis in selecting the output
of his algorithms), or completely coincidental (which is fine as far as music is
concerned). In the same vein, it is easy
to show that integral serialism, more than " ... method for pitch [rhythm, dynamics,
attack, timbre etc.] structuring" (Boulez 1966, p. 151-152), semantically speaking represents the absolute
supremacy of timbre over all other semiotic systems that act in music.3
These are just two very rough
examples of the lineal romantic ideal of music development that composers have inherited from strong non-fragmented
languages, along with the ideas of "talent,"
"genius," etc. We think these conceptions are quite outdated, just as we believe that Bach was regarded by his
contemporaries (in the beginning of the era of music printing) as we now might consider an excellent film music
composer more than a genius in the romantic sense. These same conceptions have
led to a questionable speculation operated by some composers with
respect to psychoacoustics.
These
composers have considered psychoacoustics as the new "art of orchestration."
We would like to invert this statement: there is a very little theory produced
by psychoacoustics that cannot be found in
explicit musical terms in good old orchestration manuals. Of course, the immense effort of explaining orchestration
(among other things) in terms of psychophysical sciences need not be
underestimated, but it is clear to psychoacousticians
themselves that this theory lies in an infra-semiotic field, very close
to natural phenomena (that means, in rough
terms, that psychoacoustical research stops a few inches inside the aural system). Just to
quote the most obvious example, the fact that the very limited timbral semantic segmentation
provided by certain models (cf. McAdams 1982) has been sufficient for some
composers to base compositional processes on it gives testimony of our still strongly traditional way of
thinking (that is, tied to old lineal schemes
of composition evolution, such as looking for algorithmically created timbres
as some "new" compositional tool to be exploited). What we
want to stress here is that psychoacoustical
knowledge will be extremely useful (i.e. to clarify syntactical marks and physical properties of "
musical monemes" ) once we have found the
way to link it to the field of musical semiotics. As far as we know,
this has not been attempted.
Considering
the situation exposed in this paragraph, it is not surprising that results in computer music are generally rather
meager. Another good excuse for this - and a strange one at that - is that the whole field of contemporary music is
at a critical stage. While this is not absolutely true, what is indefensible is that computer music has a very strong general connotation already. That is, we can easily define a computer
music genre, an unpardonable flaw
when we think that computers are instruments with really potentially unlimited
capabilities in sound synthesis and reproduction.
The Computer a New Musical Instrument for a New Musical
Thought
Considering the change of perspective proposed in this paper, we will briefly
proceed to outline a few possibilities for immediate direction. The first and,
most important one is the study of the computer music
instrument under the profile of what we could call transparency (or
neutrality). Transparency is a non-quality; it is the lack of linguistic and cultural connotations of an
expressive medium (the absence of "noise" ;
cf. Shannon 1949). The piano is a
clear example of a non-transparent instrument (" opaque"
). Any sound from a piano keyboard will not fail to recall to us
at least one of the different universes of language" represented by piano
literature. Therefore, we can see that total transparency is practically
impossible to attain. Transparency means, in this sense, the access the composer
has to the manipulation of the micro-structures of the synthesized sounds (i.e. single sample or group of samples)
in terms of how many parameters he/she must define for them.
For example, hardware-defined machines are not
transparent. They will force the composer to use the same synthesis technique
over and over, a great problem considering that synthesis techniques
themselves are, as we will see, "opaque." Thus, micro-programmable
machines (cf. for example DiGiugno and Kott 1981; Samson 1980) have constituted a real
breakthrough. The problem with them is that, even when they are extremely
powerful, they are still not powerful enough (in a sense, they imitate the structural limitations of traditional instruments) and they are
quite difficult to use (a factor of *opacity"
, indeed, for most composers). However, the great technological leaps Operated
by VLSI technology (cf. for example, the TMS 32020 chip, the WORDSLICE technology, the 68020 general purpose chip, the
dedicated semi-customs, etc.) will presumably solve these problems in
the not too distant future. Nevertheless, we do not think it will be possible
to solve the transparency problem completely. An "efficient"
technique will always tend to be connoted because of its data reduction schemes
("opaque" in its results), while a "flexible" one will
never be easy to handle because of the number of parameters involved ('
opaque" in its control). This cannot be avoided, but an attempt to measure the transparency" should be made in
order to select and realize more "musically powerful"
synthesis techniques.
A proposal in this direction could be the analysis of the various synthesis techniques we already possess (cf. Risset
1969; Rabiner and Gold 1974; Crochiere
and Rabiner 1983)
to establish a quantitative "transparency" factor based on some kind
of a "sample flexibility/number
of control parameters" ratio (in relation, maybe, to the Lagrange linear approximation method or non-linear approximations
like spline functions. etc.). This could be
particularly useful in the evaluation of synthesis-by-model techniques or synthesis technique aggregations. Artificial
Intelligence could be used to provide " intelligent"
automated parameter controls to improve " transparency" on non-efficient
techniques. Following the general trend of convergence of methods
between synthesis and composition tool
structuring (cf. for example the CHANT/FORMES project in Rodet,
Potard and Barriere 1984; Rodet
and Cointe 1984) some new methods for quantitative
musical analysis could be devised, in the
path of the theories of information shaped more than two decades ago
(cf. Shannon and Weaver 1963; Meyer 1967; Coons and Krahenbuehl
1958; Moles 1960). Other problems that
should be solved concern loudspeaker "opacities" ,
which play an important role in all
loudspeaker-produced music (and, of course, all reproduced music as
well). These problems are basically divided into two categories, which we could
call sound localization" and " instrument
vs. loudspeaker irradiation." To our knowledge, these two categories of problems are presently being studied separately
(the first one, cf. Kendall and Martens 1984a. 1984b; Bennett, Barker and Edeko 1985; Borish 1985; the second
one cf. Benade 1985). In our opinion it is very
important, in the perspective indicated in
this paper, that these two fields be brought together in order to provide a
general theory on loudspeaker "transparency" (a theory we
realize has a long way to go yet).
Conclusion
There are many topics that could still be discussed
widely under the point of view proposed
here. The return of subjectivity, new concepts of " tonality" and
" atonality" in the sound
reproduction era, the generative approach to analysis and composition, artificial
intelligence, non-deterministic systems, cross-synthesis techniques, the
notion of structural coherence and that of
"materials" in this perspective, etc.; these and other arguments will not find a space in this paper. In any case,
it is important to re-assert now what has already been pointed out in the beginning. We hope this paper has
presented a new way of thinking about
music, and some (by no means all) of its most important aspects and strategies.
Once again, we wish to make it clear that it is not the usefulness of systems
and theories that we are questioning (in
composition, anything is useful) but how they are used.
Bibliography
Adorno, T.W., Der getreue Korrepetitor, Frankfurt/Main,
1963. Adorn, T.W. and Eisler, H., Komposition fir den Film, Leipzig,
1977.
Avron, D.,
"Energetique Musicale ou
Semiologie de la Musique?", in Musique en Jeu, #18, Paris,
April, 1975.
Baroni, M., "Musicologia Semiotica e Critica Musicale" , in Musical Realea, 2,
pp. 29-49, Reggio Emilia,
1980.
Barrierre,
J. B., "Chreode 1: The Pathway to New
Music with the Computer?' in Contemporary Music Review, Vol. 1, Part 1,
pp. 181-202, London, 1984.
Barthes, R., "Le
Grain de la Voix," in Musique
en Jeu, #9, November 1972.
Benade, A.H., "From Instrument to Ear in a Room: Direct
or via Recording," in Journal of the
Audio Engineering Society, Vol. 33, #4, pp.
218-233, 1985.
Benjamin,
W., "Das Kunstwerk in Zeitalter seiner Technischen Reproduzierbarkeit,"
in Gesammelte Schriften,
Vol. 1/2, Frankfurt/Main, 1974.
Bennet, J. C., Barker, K., and Edeko,
R. C., "A New Approach to the Assessment of Stereophonic Sound Systems," in Journal of the Audio
Engineering Society, Vol. 33, #5, pp. 314321,
1985.
Blanchot, M., La Communaute inavouable, Editions
de Minuit, Paris, 1983.
Borish, J., " An Auditorium Simulator for Domestic
Use," in Journal of the Audio Engineering
Society, Vol. 33, #5, pp. 310-341, 1985.
Boulez, P., " Tendences de la Musique Riecente,"
in La Revue Musicale, #236, 1954.
Boulez, P., "tventuellement ...," in Releves
d'Apprenti, Editions du
Seuil, Paris, pp. 147- 182, 1966.
Boulez, P. "Doric on Remet en
Question," in La Musique en Pro jet, Ballimard-IRCAM, Paris, 1975.
Bright, W.,
"Language and Music: Areas for Cooperation," in Ethnomusicology, 7,
pp. 2632, 1963.
Buyssens, E., La Communication et l'Articulation Linguistique, Presses Universitaires
de France, Paris, 1963.
Cage,
J., Silence, Wesleyan University Press, Middletown, CT., 1973.
Chenowith, V., Melodic
Analysis and Perception, Summer Institute of Linguistics, Papua, New
Guinea, 1972.
Clynes, M., (with Nettheim, N.), Musical Score + Microstructure = Living
Music, paper presented at the 1984 International Computer Music Conference,
Paris, 1984.
Cogan, R., New Images of Musical Sound, Harvard
University Press, 1984. Cooke, D., The Language of Music, Oxford Paperbacks,
London, 1962.
Coons, E., and Krahenbuehl, D.,
"Information as Measure of Structure in Music," in Journal
of Music Theory, #2, pp. 127-161,
1958.
Court, R., "Language Verbal et Languages tsthietiques," in Musique
en Jeu, #2, pp. 14-27, 1971.
Crochiere, R. E., and Rabiner, L. R., Multirate
Digital Signal Processing, Prentice-Hall, Englewood Cliffs, NJ, 1983.
Delalande,
F., "L'Analyse des Musiques
Electro-acoustiques," in Musique
en Jeu, #8, pp. 50-56, September, 1972.
Di Giugno,
G., and Kott, J., "Presentation du Systeme 4X," in Rapport
IRCAM, 32/81, Paris, 1981.
Eco, U., Trattato di Semiotica Generale, Bompiani, Milano, 1975. Goodman,
N., Languages of Art, Bobbs-Merrill, New York,
1968.
Groddeck, G., "Musique et Inconscient," in Musique
en Jeu, #9, November, 1972, pp. 3-6, 1972
(originally published in Psychoanalytische Schriften zur Literatur
and Kunst, Limes Verlag,
Wiesbaden, 1964).
Gupta,
M., and Sanchez, E., Fuzzy Information and Decision Processes, Elsevier
Science Pub.
Co., New York, 1982.
Hanslick, E., Von Musikalisch-Scanen, Wien,
1891.
Harweg, R., "Language et Musique: Une Approche
Immanente et Semiologique,"
in Musique en
Jeu, #5, pp.
19-30, 1972.
Hassan, I., The
Dismemberment of Orpheus: Toward a Post Modern Literature, Oxford
University Press, New York, 1971.
Hjelmslev, L., Prolegomena
to a Theory of Language, University of Wisconsin. Press,
1943.
Hjelmslev, L., Essais Linguistiques, Travaux du Cercle
Linguistique de Copenhagen, Nor-disk Sp2og-og Kulturforlag, Copenhagen, 1961.
Imberty,
M., "Perspectives Nouvelles de la Semantique Musicale Experimentale,"
in Musique en Jeu,
#17,
pp. 87-110, 1975.
Imberty, M., "Le Probleme de la Mediation Semantique
en Psychologie de la Musique,"
in VS-Versus, 13, pp. 35-48, Bompiani, Milano, 1976.
Ivaskin, A., "Dall'Immagine
e la Forma al Simbolo e alla
Metafora. L'Arte Sovietica Negli
Anni '10-30 e la Musica di Oggi," in Musical Realta, 15, pp. 85-106, Reggio
Emilia.
Jakobson,
R., "Musicology and Linguistics," in Sonus,
Vol. 3, #2, pp. 12-15, 1983 (first
published
as "Musikwissenschaft and Linguistik,"
in Pillager Press, December, 1943).
Katz,
J. J., and Postal, P. M., An Integrated Theory of
Linguistic Descriptions, MIT Press, Cambridge, 1964.
Kauffman, A., Introduction iz
la Theorie des Sous-Ensembles
Flous a l'Usage
des Ingenieurs (Fuzzy
Sets Theory), Masson, Paris, 1973.
Kendall, G. S., and Martens, W. L., Spatial
Reverberation - Simulating the Spatial Enviornmerit,
paper presented at the International
Computer Music Conference, Paris, 1984a.
Kendall,
G. S., and Martens, W. L., The Role of Spectral Cues in Sound Localization
with Speakers, paper presented at the International Computer
Music Conference, Paris, 1984b.
Langer,
S., Philosophy in New Key, Mentor Books, New York, 1951.
Lientz, B. P., "On
Time Dependent Fuzzy Sets," in Information Sciences, 4, pp.
367-376, 1972.
Levi-Strauss, C., Le Cru et
le Cuit, Plon, Paris,
1964. Levi-Strauss, C., L'Hornme
Nu, Plon, Paris, 1964.
Lissa, Z., "Fonctions tsthkiques do al
Citation Musicale," in VS-Versus, 13, pp. 19-34, Bompiani, Milano, 1976.
Lotman,
J., "Il Problema del Segno e del
Sistema Segnico nella Tipologia della Cultura Russa Prima del XX Secolo," in Richerche Semiotiche, Lotman and Uspenskij, eds.), Einaudi, Torino, 1973.
Lyotard, J. F., La
Condition Postmoderne, Editions de Minuit, Paris, 1979.
Manoury, P., "The Role of the
Conscious" , in Contemporary Music Review, Vol.
1, Part 1, pp. 147-156, London, 1984.
Mamdani, E. H., and Gaines, B. R., (eds.) Fuzzy Reasoning
and Its Applications, Academic Press,
New York, 1981.
Martinet,
A., Elements de Linguistique Generale,
Colin, Paris, 1960.
Mayer, G., "Dalla Musica nei Media alla Musica par i Media. Pensieri per un'Estetica della
Musica 'Radiogenica',".
in Musica/Recdth, 16,
pp. 119-143, Reggio, Emilia,
1985.
McAdams, S., "Spectral Fusion and the Creation of
Auditory Images," in Music, Mind, and Brain,
Clynes,
M., ed., Plenum Pressm New York, 1982.
McCaffery, S.,
"Marshall McLuhan: Linguaggio
e Musica," in Musical Realta,
10, pp. 69-80, Reggio, Emilia,
1983.
McLuhan, M., The Gutenburg Galaxy, University of Toronto Press, Toronto,
1962. McLuhan, M., Understanding Media, McGraw-Hill,
New York, 1964.
Meyer,
L., Emotion and Meaning in Music, University of Chicago Press, Chicago,
1956.
Meyer,
L., "Meaning in Music and Information Theory," in Music the Arts
and Ideas, pp. 5-21, University of Chicago Press, Chicago, 1956.
Minsky, M., ed., Semantic
Information Processing, MIT Press, Cambridge, MA, 1968.
Moles, A.
M., "L'Analyse des Structures du Message Poetique aux Differents Niveaux de la Sensibilitie," in Poetics, Paustwowe Wydanictvo Naukowe, Warszava, 1960.
Molino, J.,
"Fait Musical et Semiologie de la Musique," in Musique
en Jeu, #5, pp. 3-17. Nattiez, J. J., "Situation de la Semiologie
Musicale," in Musique en Jeu, #10, pp. 3-11,1971.
Nattiez, J. J.,
"De la Semiologie a la S'emantique
Musicale," in Musique en Jeu, #17, pp. 310, 1975.
Nattiez, J. J., Fondements d'une Semiologie de la Musique, Editions du Seuil, Paris, 1975.
Nattiez,
J. J., "La Funzione Semantica
nella Musica," in VS-Versus,
#13, pp. 2-4, Bompiano, Milano, 1976.
Nettl, B., "De Quelques Methodes Linguistiques Appliquees a l'Analyse Musicale," in Musique en Jeu, #5,
pp. 61-66, 1971.
Osmond-Smith, D., "The Iconic Process in Musical
Communication," in VS-Versas, #3, pp. 31-42, Mauri
Editore, Milan, 1972.
Pal, S. K., Fuzzy Mathematical Approach in Pattern
Recognition Problems, Wiley, New York,
1985.
Pike, K. L.,
Phonemics, University of Michigan Press, Ann Arbor, 1947.
Quillian, M. R.,
"Semantic Memory," in Semantic Information Processing, Minsky, ed., MIT Press,
Cambridge, MA., 1968.
Rabiner, L. R., and Gold,
B., Theory and Application of Digital Signal Processing, Prentice-Hall,
Englewood Cliffs, NJ, 1974.
Restivo, G., "La Desemiotizzazione,"
in Alfa,beta, #70, p. 26, Milano, 1985. Ricoeur, P., "Structure et Hermeneutique," in Esprit, Paris, 1963.
Risset, J. C., An
Introductory Catalogue of Computer Synthesis Sounds, Bell Telephone
Laboratory Official File Copy, 1969.
Rodet, S., and Cointe, P., "Composition and Scheduling of
Processes," in Computer Music Journal,
8:3, pp. 15-21, 1984.
Rodet, X., Potard,
Y., and Barriere, J. B., "The CHANT Project:
From Synthesis of the Singing Voice to Synthesis in General," in Computer
Music Journal, pp. 32-50, 1984.
Rosset, C., L'Objet
Singulier, Editions de Minuit,
Paris, 1979.
Ruwet, N., Language, Musique, Poesie, Editions du Seuil, Paris, 1972.
Ruwet, N.
"Theorie et methodes dans les etudes
musicales: quelques Remarques
Retrospectives
et Preliminaires," in Musique
en Jeu, #17, pp. 11-36, 1975.
Samson, P., " A General-purpose Digital
Synthesizer," in Journal of the Audio Engineering Society,
Vol. 28, #3, pp. 106-113, 1980.
Saussure, F. de, Cours de Linguistique Generale, Payot, Paris, 1922.
Schmucker, K. J., Fuzzy
Sets, Natural Language Computations and Risk Analysis, Computer Science Press, Rockville, MD.
Shannon, C.,
"The Mathematical Theory of Communication," in Bell System Technical
Journal, July and October, 1948.
Shannon, C.,
and Weaver, W., The Mathematical Theory of Communication, University of Illinois Press,
1963.
Skala, H. J., Termini, S., and Trillias, E., eds., Aspects of Vagueness, Reidel Publishing Company, Boston, MA, 1984.
Springer, G. P., "Language and Music: Parallel and Divergencies," in For Roman Jakobson,
pp.
504-613, Mouton, The Hague, 1956.
Stefani, G., Introduzione
alla Semiotica della Musica,
Sallerio, Palermo, 1976.
Stoianova, I., "Musica
e Tecuologia - Note Sull'attuale
Ricerca Musicale," Musical Realth, 11, pp. 123-134, Reggio
Emilia, 1983.
Stravinsky,
I., Poetics of Music, Harvard Paperback, Cambridge, MA, 1942.
Thomson, W., "Functional
Ambiguity in Musical Structure," in Music Perception, Vol. 1, #1,
pp. 3-27, 1983.
Vattimo, G., and Rovatti, P. A., eds.,
Ii Pensiero Debole, Feltrinelli, Milano, 1983. Vattimo, G., La Fine della
Modernita, Garzanti, Milano, 1985.
Wong, C. K., Fuzzy Points
and Local Properties of
Fuzzy
Topology, University
of Illinois Press, Champaign-Urbana, 1973.
Xenakis, I., "Les Chemins de la
Composition Musicale," in Le Compositeur et l'Ordinateur, Centre George Pompidou,
IRCAM/EIC, Paris, pp. 13-32, 1981.
Yates, F., The Art of Memory, Routledge and Kegan
Paul, London, 1966.
Zadeh, L. A., "Fuzzy Sets," in Information and
Control, #8, pp. 338-353, 1965. Zadeh,
L. A., "Fuzzy Algorithms," in Information and Control, #12,
pp. 93-102, 1968.
Zadeh, L. A., "Quantitative
Fuzzy Semantics," in Information Sciences, 1971:3, pp. 159- 176,
1971a.
Zadeh, L. A., King-Sun, F., Kokichi,
S., and Shimura, M., Fuzzy Sets and their Applications to Cognitive and Decision
Processes, Academic Press, Inc.,
New York, 1975.
1
Paper presented at the 1986
International Computer Music Conference, Vancouver, Canada.
2
From a joke my grandfather often used
to tell; also in C. Bernardini "Che cose una legge fisica"
, p. 77, Ed.
Riuniti Rome, 1983.
3 This
is explained by the obvious supremacy which natural structures, i.e. timbres,
have even with a weak second-level
articulation over abstract, second articulation structures that do not possess
first articulation foundations - the serialized parameters (cf. on this
subject the enlightening, provocative and much criticized Ouverture
in Levi-Strauss 1964, pp. 22-38; and also Martinet 1960).